In summer of 2022, I first heard of a new autocompletion tool named “GitHub Copilot” and was so thrilled by it that I immediately signed up for the waitlist. That was before the appearance of ChatGPT and all of that crap, but it was made by the same company.
In this post, I’ll discuss why this tool, while being quite impressive and maybe even useful (which is actually quite challenging for a large language model), is maybe not that efficient and might be violating many licenses.
I’m writing this post as someone who has used Copilot for more than a year for everything and know tries to get rid of it.
How useful is Copilot really?
The first thing I can think about is that Copilot is like any other LLM: even though it seems like it knows a lot, it tends to hallucinate. For example, it could write a simple function instantly, but with bugs ranging from unexpected output to crashes or vulnerabilities (e.g. buffer overflows which can lead to arbitrary code execution). This is not really an issue for big projects as there are usually one or two other people reviewing the code, and they probably kbnow how to check for vulnerabilities. But for very small projects managed by only one person and maybe used by the entire industry, this is a huge issue. Imagine what would happen if the random person in nebraska from the XKCD comic below was using Copilot without checking the code it was writing:
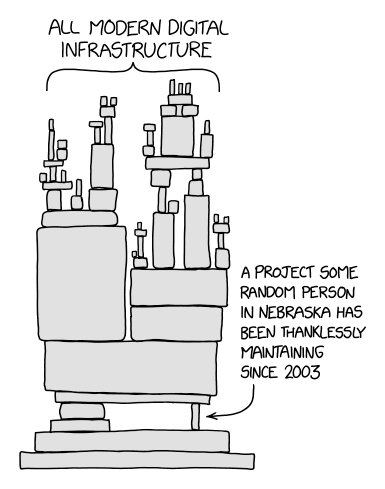
This leads us onto our next point: Copilot is kind of counter-productive. Because it can’t check the documentation of the library / programming language / framework you’re working with, it sometimes gives you pieces of code that have no chance of working. Copilot also makes you forget how to check documentation which is often times much faster than just trying to get the LLM to give you some code that isn’t downright wrong.
AI was actually never intended to get to the level of an LLM: it was really just intended to recognize objects on an image, or words in an audio file. The way an LLM works (finding the most likely word - or code symbol in Copilot’s case - after another) also doesn’t feel very smart. Sure, it makes it seem smart, but that’s also why LLMs hallucinate; when you ask ChatGPT a question, it will start writing an answer and won’t go back to correct itself or tell you it doesn’t know. This is also why a simple web search is always better than asking ChatGPT (plus you won’t use up as much resources).
Edit: As some people pointed out on the tildes topic of this post, Copilot is quite useful when writing boilerplate. I also find it’s quite good for writing things like Bash scripts or configuration files.
What using Copilot daily means for a developer
OK, enough with rambling about how bad LLMs are.
Another big problem with GitHub Copilot is how you lose skills a developer should have. This is something Wouter Groeneveld wrote about on his blog: ChatGPT Is Worse For Students Than Stack Overflow. You just loose the ability to search for documentation correctly, or even (in his students’ case) don’t learn the programming language. This happens a lot to me, and that’s why I decided to solve Advent of Code 2023 problems with Copilot disabled. I mean, I couldn’t find enough time for it after the 5th day and then lost interest in it :-), but the experiment was interesting: on the first day I struggled a bit to find the documentation but after that, I was able to write programs at what felt like a much faster pace than with Copilot enabled.
I guess this is due to me actually checking the documentation before writing my code and finally understanding iterators correctly. It may be better to use GitHub Copilot after reading the entire documentation of what you’re using, but then what’s the point?
What Copilot means for all developers
Remember, Copilot is an AI model and as such, it has to chew a whole bunch of data before being useful. The training data for Copilot comes from - you guessed it - GitHub’s public repositories. GitHub/Microsoft/OpenAI never asked developers for consent, or rather, they made developers accept their terms of service, which like any FAANG company’s ToS just says they basically do whatever they want with the data you publish.
It could be argued that this data collection isn’t as bad as some others: at least they didn’t put cameras in public places like universities1 or crawl the entire internet for text or image contents2. It could also be said that it’s Microsoft’s platform and they are free to do whatever they want with their user’s data.
Either way, this stands on the red line of free (as in freedom) software licenses like the GPL, because the copyright holders of projects under those licenses (i.e. all contributors to a GitHub repository) never explicitly allowed this usage.
GitHub Copilot is quite easily within the bounds of what most would consider to be copyright infringement, and is therefore in breach of both copyleft licenses such as the GPL and proprietary licenses that withhold the permission to view or otherwise disseminate the source code of a program.3
The fact that GitHub’s ToS allows them to scan your code doesn’t even mean that they are legally allowed to: otherwise anybody could create their own GitHub-like platform with terms that would allow them to do whatever they want with the code, and then upload someone else’s code. In this case, the decision of what could be done with code is (hopefully) not decided by some terms of service but by the license of said code (or at least it should, I’m not a lawyer).
Conclusion
Copilot is not great, but I still use it for writing configuration files. This website is mostly free from its code and text and I will try to continue that trend to hopefully stop using Copilot altogether. I will also never pay for it (right now it’s free for me as I’m in high school). As for licensing, I’ll let Wouter Groeneveld sum up my thoughts:
It’s pretty clear to me that without the help of the government to direct how society should handle this, greedy gobblers will keep on gobbling.4
I’m off, see you in 2024.
-
CU Colorado Springs students secretly photographed for government-backed facial-recognition research – The Denver Post, A Duke study recorded thousands of students’ faces. Now they’re being used all over the world - The Chronicle ↩︎
-
Your Personal Information Is Probably Being Used to Train Generative AI Models - Scientific American ↩︎
-
On the Nature of AI Code Copilots - Free Software Foundation ↩︎